Governance-as-Design
Eval, audit, and rollback as design inputs for clinical-adjacent AI. Not review-stage checkboxes.
Blake Aber · Predicate Ventures · 2026
Most enterprise AI programs treat governance as a retrofit. Build the model. Ship the demo. Hand it to compliance for review. Compliance flags the issues that should have been designed in. Engineering re-scopes. Timeline slips. The pilot looks impressive in the steering-committee deck and never makes it to production.
The programs that actually ship at health-payer scale do not work this way. The same discipline shows up in how healthcare AI ships around the enterprise blocker cycle: scope is decided before anything is built. They treat governance as a design input, co-authored with compliance and clinical risk from day 1, not handed off at month nine. The eval harness, the audit boundary, the rollback surface, and the clinician-facing confidence signal are scoped before the model is selected. They shape what gets built. They are not artifacts produced after.
This is the distinction that decides whether a program ships.
The four primitives
Eval harness. Not the test set. The standing infrastructure that runs the model against named scenarios continuously, tracks output drift over time, and flags when the distribution of inputs has shifted enough that the validation set no longer covers production reality. The eval harness is what turns "did the model pass at week zero" into "is the model still passing." Designed in: dashboards, alerting, ownership. Designed out: silent failure.
Audit boundary. Not the audit log. The decision about which decisions, at what granularity, with what retention, are recorded and traceable. The boundary is where the system commits to "this output, with this evidence, was produced under these conditions." Most programs draw the audit boundary too narrow (model-in / model-out, no upstream context) or too wide (every keystroke, no signal). The audit boundary that lets a clinician defend a decision under regulatory review is a deliberate scoping call, not a logging-volume question.
Rollback surface. Not the model-version manifest. The operational mechanism that takes a deployed model out of production within a defined window (minutes, not weeks) when something is going wrong. Rollback surface includes the human authority (who can pull the model), the technical mechanism (how the model is pulled), the fallback path (what happens to in-flight requests), and the post-rollback audit (what's reconstructed from the audit boundary). Most programs treat rollback as something they'll figure out if needed. The programs that ship treat rollback as the first thing they design.
Clinician-facing confidence signal. Not the confidence score. The decision about how the model communicates its uncertainty to the clinician, in language and at a granularity that lets the clinician calibrate when to override. A 0.87 confidence number is useless. A signal that says "this output is in a region where the model has historically had a 12% override rate at your institution" is calibration. Confidence signaling is where most clinical-adjacent AI quietly fails. The model may be 90% accurate, but if the signal trains the clinician to trust it on the 10% where it fails, deployment is worse than no model at all.
What "co-authored from day 1" actually looks like
Co-authored from day 1 doesn't mean compliance attends the kickoff. It means the eval-harness ownership, the audit-boundary scope, the rollback authority, and the confidence-signal vocabulary are decided before the model is selected. The model is selected partly on which models can satisfy those four primitives, not just on raw accuracy.
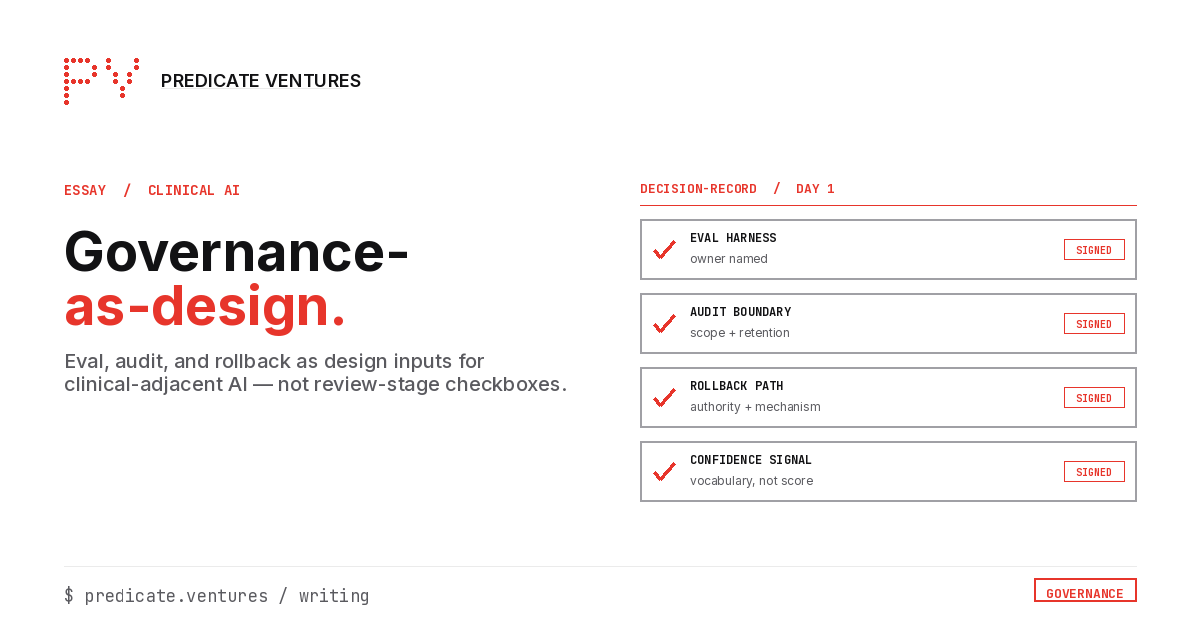
In practice, this looks like a four-way decision-record signed at week one:
- The eval harness owner is named (a specific person, not "the platform team")
- The audit boundary is scoped (specific decision granularity, retention period, evidence schema)
- The rollback path is authored (named authority, named mechanism, named fallback)
- The confidence-signal vocabulary is sketched (what the clinician sees, not the raw probability)
The decision-record exists before any model is procured. It is signed by AI, compliance, clinical leadership, and engineering. It is updated when load-bearing decisions change. The decision-record is the artifact that distinguishes design-input governance from review-end governance.
Three signs your program is design-input, not review-end
-
Compliance can answer "what would a rollback look like?" without consulting engineering. If compliance has to ask, rollback is engineering-owned, which means it's review-end.
-
Clinical leadership has approved the confidence-signal vocabulary, not the confidence-score format. If clinical leadership signed off on "we'll surface a 0-1 confidence value," that's signal-as-checkbox. Calibration is a vocabulary question, not a numeric-range question.
-
The eval harness is running against last quarter's input distribution, not last year's validation set. If the harness hasn't been updated since model selection, it's not a harness. It's a snapshot.
Programs failing all three are review-end. Programs passing all three have the design-input discipline that ships clinical-adjacent AI at scale.
Why this matters now
Two pressures are converging. Regulatory: the AI-governance posture that was sufficient for cloud-era enterprise software is not sufficient for clinical-adjacent AI. Auditors are starting to ask design-input questions, not review-end questions. Programs without design-input artifacts are going to discover this expensively. Operational: as model capability plateaus and converges across vendors, the structural advantage in health-payer-scale AI shifts to the orgs with the harness, audit, and rollback discipline to deploy any model safely. The parallel in regulated legal work is the AI governance infrastructure that policy alone can't catch, where the prevention lives in the pipeline, not the policy document. The differentiator stops being which model and starts being which infrastructure.
The retrofit programs build impressive demos. The design-input programs build production systems. The difference is not which models you select. It is what you decide before the models are selected, and who owns each decision when reality changes.